编译原理作业 exercise-3
状态迁移图或语法树编程绘制
利用画图工具Graphviz绘制如上的状态迁移图,要求提交对应的GV代码。
参考如下的网址进行学习:
digraph main {
rankdir = LR;
node [shape = circle] A, B, C, D;
node [shape = doublecircle] E, F;
A -> D [label = "0"];
B -> A [label = "0"];
B -> C [label = "1"];
C -> A [label = "0"];
C -> F [label = "1"];
D -> B [label = "0"];
E -> B [label = "0"];
E -> C [label = "1"];
F -> A [label = "1"];
F -> E [label = "0"];
}
生成图片
dot -Tpng 图1.dot -o 图1.png

另外,Graphviz提供了C语言、Java语言或Python语言等相对接的编程接口,请学习后通过编程实现生成如上状态迁移图对应的GV代码。
学习的目的:编译原理实验需要把语法分析生成的语法树进行图形化显示。
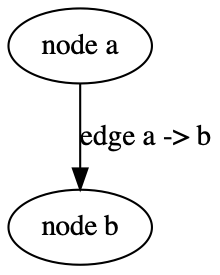
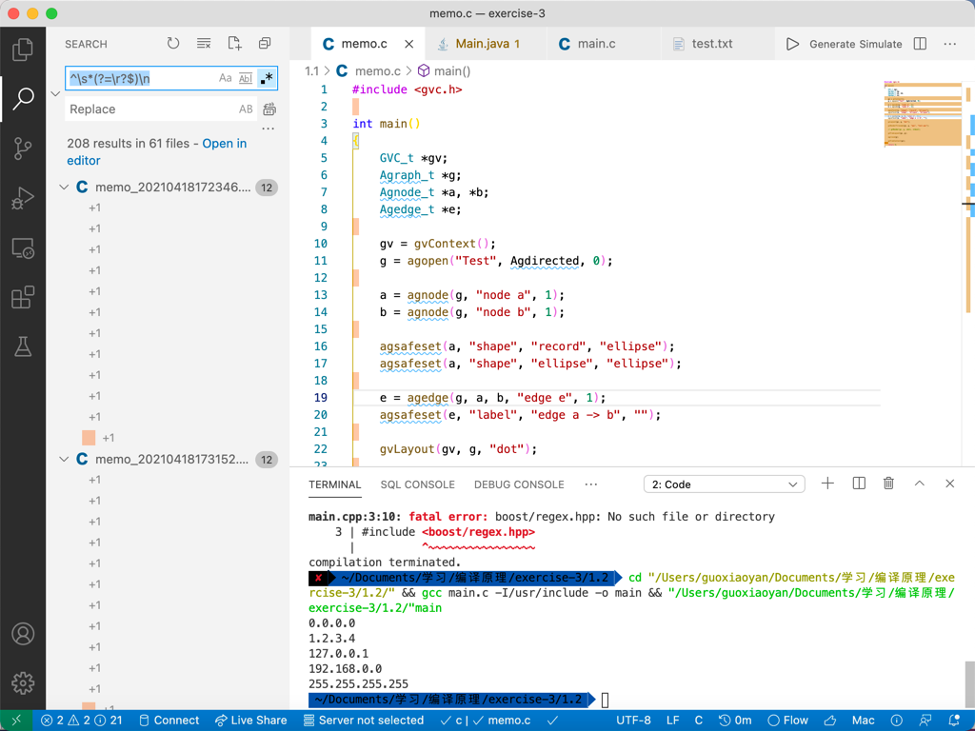
下面是利用Graphviz提供的C语言接口编写的一个C程序的Memo,这个程序可生成一个test.eps矢量图。请参考。
#include <gvc.h>
int main()
{
GVC_t *gv;
Agraph_t *g;
Agnode_t *a, *b;
Agedge_t *e;
gv = gvContext();
g = agopen("Test", Agdirected, 0);
a = agnode(g, "node a", 1);
b = agnode(g, "node b", 1);
agsafeset(a, "shape", "record", "ellipse");
agsafeset(a, "shape", "ellipse", "ellipse");
e = agedge(g, a, b, "edge e", 1);
agsafeset(e, "label", "edge a -> b", "");
gvLayout(gv, g, "dot");
gvRenderFilename(gv, g, "eps", "test.eps");
// gvRender(gv, g, "dot", stdout);
gvFreeLayout(gv, g);
agclose(g);
gvFreeContext(gv);
return 0;
}
通过如下的命令进行编译。
gcc-10 -o memo memo.c `pkg-config --libs --cflags libgvc`
然后运行
./memo
即可生成test.eps。
如果要生成其它类型的图片格式,请修改gvRenderFilename的参数,如产生png文件:
gvRenderFilename(gv, g, "png", "test.png");
针对正规式或正则表达式开展具体的使用写成课程报告,要求提交源代码和实验截图。
学习Java语言的正则表达式,并编写程序在文件中查找特定模式的字符串,要求针对IPV4地址字符串检查。
思路
运用String中的matches方法:要匹配的串.matches(正则表达式),若匹配成功则会返回True。
- 任何一个1位或2位数字,即0-99:
\d{1,2} - 任何一个以1开头的3位数字,即100-199:
1\d{2} - 任何一个以2开头、第2位数字是0-4之间的3位数字,即200-249:
2[0-4]\d - 任何一个以25开头,第3位数字在0-5之间的3位数字,即250-255:
25[0-5] - 把它们组合起来,就得到一个匹配0-255数字的正则表达式了:
(\d{1,2})|(1\d{2})|(2[0-4]\d)|( 25[0-5]) - IPV4由四组这样的数字组成,中间由.隔开,或者说由三组数字和字符.和一组数字组成,所以匹配IPV4的正则表达式如下:
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5])) - 添加限制条件,前后要么是边界,要么是非数字:
(?<=(\\b|\\D))(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))(?=(\\b|\\D))
实现
代码
import java.io.*;
public class Main {
public static void main(String[] args) {
String regex = "(?<=(\\b|\\D))(((\\d{1,2})|(1\\d{2})|(2[0-4]\\d)|(25[0-5]))\\.){3}((\\d{1,2})|(1\\d{2})|(2[0-4]\\d)|(25[0-5]))(?=(\\b|\\D))";
String str;
try {
BufferedReader in = new BufferedReader(new FileReader("test.txt"));
while ((str = in.readLine()) != null) {
if (str.matches(regex))
System.out.println(str);
}
}
catch (IOException e) {}
}
}
编译
javac Main.java
运行
java Main
测试数据在test.txt,其中含有合法ipv4地址也有非法的:
abcd
a.b.c.d
abcd.efgh.ijkl.mnop
0.0.0.0
1.2.3.4
1.2.3.4.5
127.0.0.1
192.168.0.0
255.255.255.255
255.255.0.256
256.256.256.256
300.300.300.300
1234.5678.9012.3456
123456.789
1/2/3/4
[1.2.3.4]
1.2.a.b
运行后得到的结果为:
0.0.0.0
1.2.3.4
127.0.0.1
192.168.0.0
255.255.255.255
过滤成功!
学习C语言中的利用regcomp/ regexec函数进行正则表达式匹配,并编写程序在 文件中查找特定模式的字符串,要求针对IPV4地址字符串检查。
思路
正则表达式略有不同,但推导步骤与上面相同:
^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$
regex_t是一种特殊的格式,先用regcomp将正则转换为这种格式,再使用regexec判断输入的字符串是否符合规则。
实现
代码
#include <stdio.h>
#include <regex.h>
int main(int argc, const char * argv[])
{
FILE *fp = fopen("test.txt", "r");
char *pregexstr = "^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$";
char ptext[100];
regex_t oregex;
regcomp(&oregex, pregexstr, REG_EXTENDED|REG_NOSUB);
while (1) {
fscanf(fp, "%s", ptext);
if (feof(fp))
break;
if (regexec(&oregex, ptext, 0, NULL, 0) == 0) {
printf("%s\n", ptext);
}
}
regfree(&oregex);
fclose(fp);
return 0;
}
编译
gcc main.c -o main
运行
./main
结果同上。
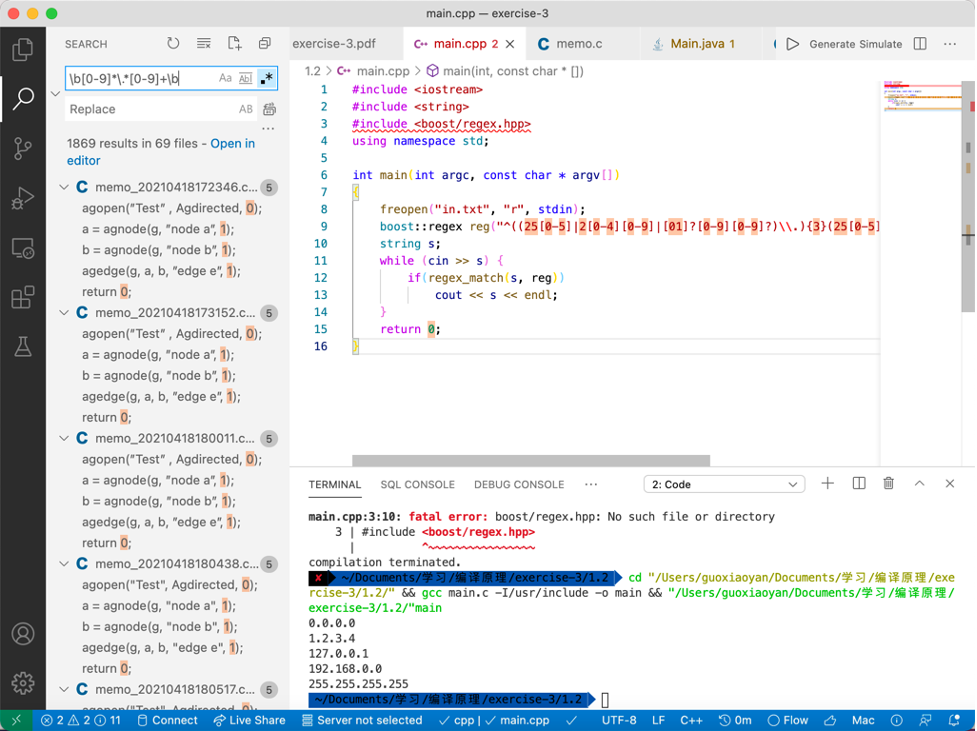
学习C++语言中利用boost库的正则表达式进行正则表达式匹配,并编写程序 在文件中查找特定模式的字符串,要求针对IPV4地址字符串检查。
思路
正则表达式同上,保存在reg中;使用regex_match判断输入的串是否与正则相匹配。
实现
代码
#include <iostream>
#include <string>
#include <boost/regex.hpp>
using namespace std;
int main(int argc, const char * argv[])
{
freopen("in.txt", "r", stdin);
boost::regex reg("^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$");
string s;
while (cin >> s) {
if(regex_match(s, reg))
cout << s << endl;
}
return 0;
}
编译
gcc main.c -I/usr/include -o main
运行
./main
结果同上。
Ultraedit、VScode、Atom等常用工具都支持正则表达式查找特定模式的字符 串,请选择一种编辑器说明正则表达式的支持状况,并截图举例查找特定模式 的字符串。(任选一个工具)
VScode中可以使用正则表达式(格式同上面C/C++程序)查找特定模式的字符串。
例如:
使用\b[0-9]*\.*[0-9]+\b查找所有十进制整数和小数:
使用^\s*(?=\r?$)\n匹配所有空白行:
使用\b0[xX]([0-9a-fA-F])\b匹配所有十六进制数等等。
在常用的Linux Shell命令中,grep、awk与sed等命令都支持正则表达式,而另 外一些命令如ls、cp与find命令支持的是通配符,两者是不同的。请试比较并实 验验证。(两类命令各任选一个)
grep
grep的命令格式:grep [OPTIONS] PATTERN [FILE...],例:
查找main.c中带有regex的行:
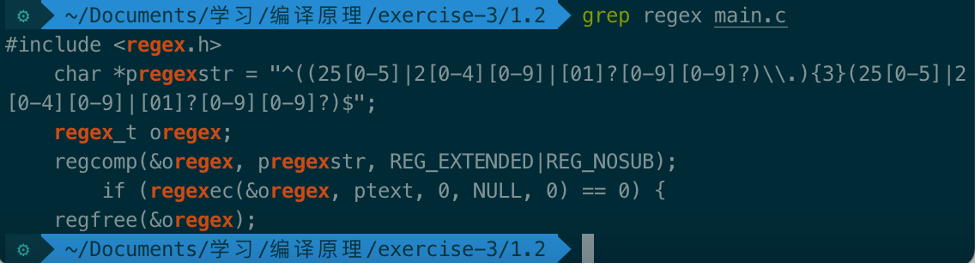
尝试使用正则表达式:
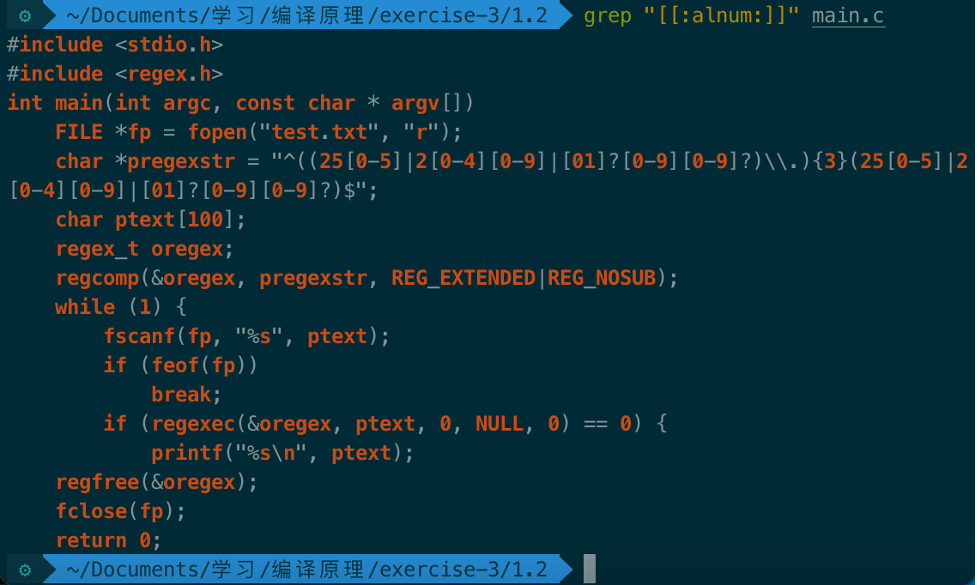
由于[:alnum:] 代表所有的大小写英文字符和数字,即0-9, A-Z, a-z。查找全部串:
查找以#开头的行,使用-n打印出行号:

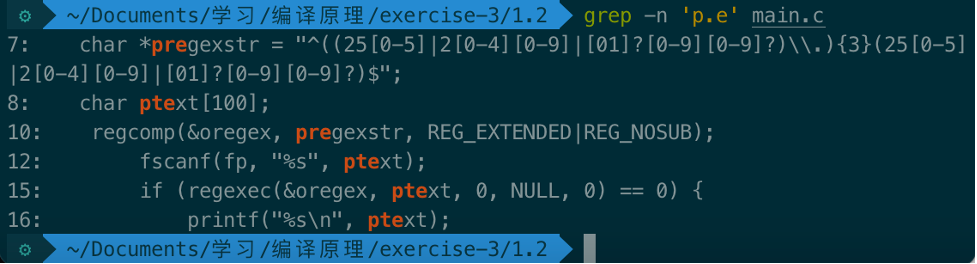
.可代表任意符号,以此查找p和e中间隔1个字符的词:
*代表可重复多个,以此查找一个b接不论数量的o的串:

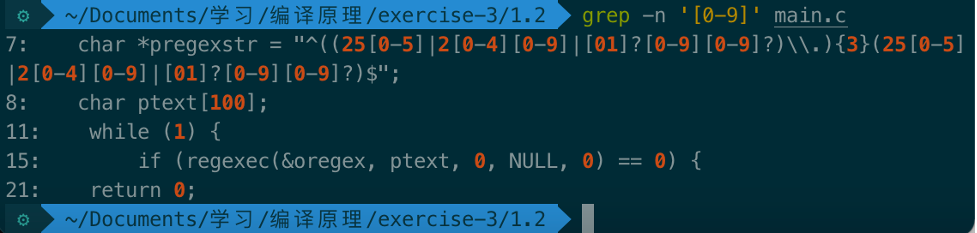
[]代表匹配中间任意字符,以此查找所有的数字:
-E选项使用扩展正则表达式,还是用之前C/C++程序中的正则表达式,使用grep命令进行匹配ipv4地址:
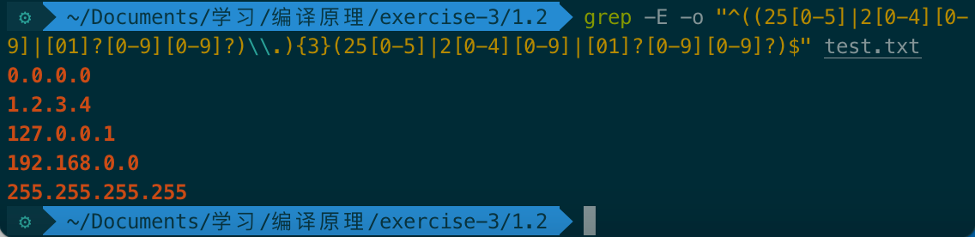
可达到相同的目的。
ls
ls + 正则表达式直接打印出当前目录下所有符合条件的文件名,但它的正则表达式与上面grep的语法略有不同,被称为通配符。
/exercise-3/1.2文件夹下所有文件如下:

*代表任意个数个字符,查找所有m开头的文件:

?代表只有1个字符,查找所有main.开头末尾只有1个字符的文件:

可见main.cpp并没有被包括进来。
[]是选择其中一个字符,只要在[]内的字符都可以被匹配;查找以Main或main开头的文件:

今晚更腾讯TiMi二面